
GRU (Gated Recurrent Unit) in Deep Learning is an advanced recurrent neural network architecture designed to solve the vanishing gradient problem found in traditional RNNs. By simplifying the LSTM structure while maintaining strong sequence modelling performance, GRU has become a popular choice for text generation, time-series forecasting, and NLP tasks.
GRU (Gated Recurrent Unit)
- GRU is a type of Recurrent Neural Network (RNN) designed to solve the vanishing gradient problem that standard RNNs face when learning long sequences.
- GRUs simplify the LSTM architecture by combining the forget and input gates into a single update gate and merging the cell state and hidden state.
- This simplification leads to fewer parameters and faster training while maintaining performance close to LSTM on many tasks.
Comparison: RNN vs LSTM vs GRU
- A standard RNN relies on a hidden state to retain information over time.
- In contrast, LSTM and GRU enhance this by using gate mechanisms that control which information should be remembered or discarded before updating the hidden state.
- Additionally, LSTM includes a separate cell state that functions as a form of long-term memory, whereas GRU uses only a hidden state to carry memory.
- But in both models, once the hidden state (and the cell state in the case of LSTM) is computed at time step t, it is fed back into the recurrent unit along with the input at the next time step (t+1) to generate the updated hidden state (and cell state). This process continues iteratively through t+2, t+3, and so on, until the specified number of time steps (n) is completed.
GRU Architecture Key Points (How GRU Works)
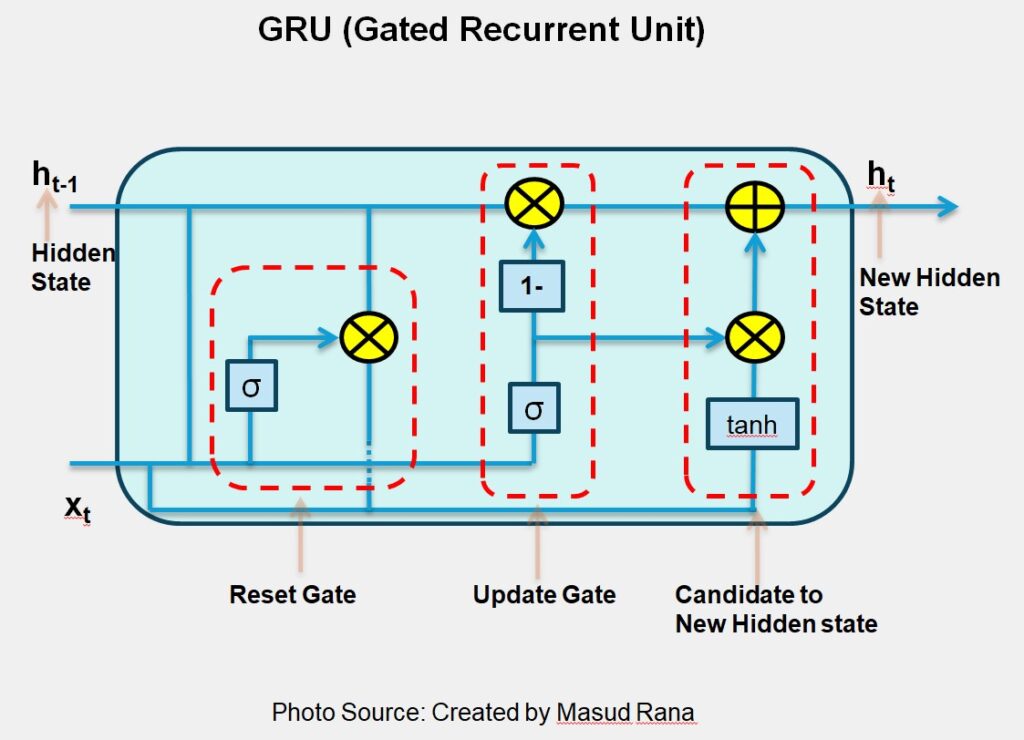
1. Reset Gate(rt)
- Controls how much past information to forget.
- Takes previous hidden state (hₜ₋₁) and current input (xₜ).
- Applies weights and bias, then passes through sigmoid function.
- Output values between 0 and 1 decide:
- 0 → forget the info
- 1 → keep the info
- Value between → partially keep
- Multiply the reset gate output with the previous hidden state.
- This “resets” irrelevant information from past memory.
Reset Gate Equation : rt =σ ( Wr * [ ht−1, xt ])
2. Update Gate (zt)
- Controls how much of the past information to keep.
- Similar to reset gate, but with different weights and bias.
- Again uses sigmoid function to decide how much past vs new info to keep.
Update Gate Equation: zt =σ ( Wz * [ht−1 , xt ]) where σ is the sigmoid activation.
3. Hidden State Candidate(h t~)
- Combine the reset hidden state with current input.
- Apply weights, bias, and pass through tanh to get a new memory candidate.
Hidden State Candidate Equation : h t~ =tanh (W * [ rt ∗ ht−1 , xt ])
4. Final Hidden State (hₜ)
- Multiply update gate output with the new candidate memory.
- Multiply (1 – update gate) with the previous hidden state.
- Add both results to get the new hidden state.
Final Hidden State Equation : ht =(1−zt) ∗ ht−1 + zt∗ ht~
The new hidden state is passed to the next time step (t+1, t+2, …, t+n) along with the next input. This continues until the whole sequence is processed.
Why Use GRU?
- Fewer parameters = faster to train
- Works well on smaller datasets and simpler tasks
- Captures dependencies in sequences effectively
- Great alternative when you want performance close to LSTM but less computation
Python Implementation for GRU (Fashion Product Description Generator)
# Import Necessary Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, GRU, Dense,Dropout
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
# Step 1: Load fashion dataset
df = pd.read_csv('/content/fashion_descriptions.csv')
fashion_descriptions = df['description'].astype(str).tolist()
# Step 2: Preprocess the text data
tokenizer = Tokenizer()
tokenizer.fit_on_texts(fashion_descriptions)
total_words = len(tokenizer.word_index) + 1
# Create input sequences using n-gram method
input_sequences = []
for line in fashion_descriptions:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# Pad sequences
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre')
# Create predictors and label
X = input_sequences[:, :-1]
y = input_sequences[:, -1]
y = tf.keras.utils.to_categorical(y, num_classes=total_words)
# Train-validation split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 3: Build the LSTM model
model_gru = Sequential([
Embedding(total_words, 100, input_length=max_sequence_len - 1),
GRU(150, return_sequences=True),
Dropout(0.2),
GRU(100),
Dropout(0.2),
Dense(100, activation='relu'),
Dense(total_words, activation='softmax')
])
model_gru.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_gru.summary()
# Step 4: Train the model
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history_gru = model_gru.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=75,
batch_size=64,
callbacks=[early_stop],
verbose=1
)
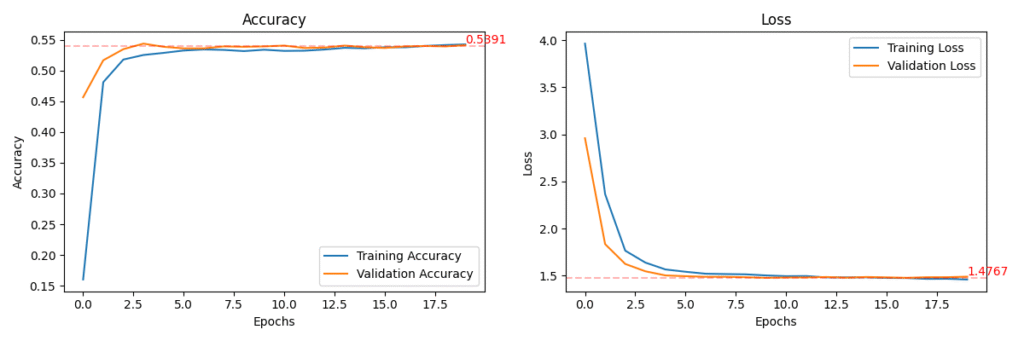
# Step 5: Plot performance
def plot_training_history(history, val_loss, val_acc):
plt.figure(figsize=(12, 4))
# Accuracy subplot
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.axhline(y=val_acc, color='r', linestyle='--', alpha=0.3)
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
# Annotate final validation accuracy
plt.text(len(history.history['accuracy']) - 1, val_acc,
f'{val_acc:.4f}', color='red', fontsize=10, verticalalignment='bottom')
# Loss subplot
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.axhline(y=val_loss, color='r', linestyle='--', alpha=0.3)
plt.title('Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# Annotate final validation loss
plt.text(len(history.history['loss']) - 1, val_loss,
f'{val_loss:.4f}', color='red', fontsize=10, verticalalignment='bottom')
plt.tight_layout()
plt.savefig('GRU_Accuracy_Loss.png')
plt.show()
# Evaluate
val_loss, val_acc = model_gru.evaluate(X_val, y_val, verbose=1)
print(f"\nValidation Accuracy: {val_acc:.4f}")
print(f"Validation Loss: {val_loss:.4f}")
# Plot training performance
plot_training_history(history_gru, val_loss, val_acc)
# Generate sample predictions
def generate_text(seed_text, next_words, model, tokenizer, max_sequence_len):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted_probs = model.predict(token_list, verbose=0)
predicted_index = np.argmax(predicted_probs, axis=-1)[0]
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted_index:
output_word = word
break
# Stop if predicted word is unknown (rare case)
if output_word == "":
break
seed_text += " " + output_word
return seed_text
print("\nGenerate fashion descriptions:")
seed_input = input("Enter seed text: ")
generated_text = generate_text(seed_input, next_words=10, model=model_gru, tokenizer=tokenizer, max_sequence_len=max_sequence_len)
print(generated_text)
Output:
Generate fashion descriptions:
Enter seed text: This vintage sweatshirt
This vintage sweatshirt is made of suede in gray color color styling styling
