
Association Rule Mining
- Association Rule Mining is a technique used to find patterns in data, particularly in transaction databases.
- It helps uncover relationships between items that are frequently bought together.
Goal: Discover rules like:
“IF a customer buys Bread and Butter, THEN they are likely to buy Jam.”
This is very common in market basket analysis in retail and e-commerce.
Real-World Example: Fashion Retail
Suppose we’re analyzing shopping patterns in a fashion store:
Customers who buy denim jackets often also buy white sneakers.
Customers who buy leggings and sports bras often also buy yoga mats.
This helps with:
Product placement
Bundle offers
Recommendation engines
What Are Association Rules?
Association rules are implications that look like this:
IF {Item A, Item B} THEN {Item C}
Here:
The antecedent (or condition) is
{Item A, Item B}The consequent (or result) is
{Item C}
These rules help us understand patterns like:
“Customers who buy leggings and sports bras are likely to buy item .”
Key Terms:
01. Itemset:
- An itemset is simply a collection of two or more items that appear together in a transaction.
- Example:{leggings, sports bras} is an itemset, more specifically, a 2-itemset because it contains two items.
02. Frequency and Support:
- To evaluate how significant an item or itemset is, we use two basic metrics:
- Frequency: How many times an item or itemset appears in the dataset.
- Support: The proportion of transactions that contain the item or itemset.
Support(A) = Transactions containing A / Total transactions
- Example:
- If {leggings} appears in 8 out of 20 transactions, its support is: Support(leggings) = 8 / 20 = 0.4
- If {leggings, sports bras} appears in 5 out of 20 transactions, then: Support({leggings, sports bras}) = 5 / 20 = 0.25
- Example:
03. Confidence: Measuring Rule Strength:
- How often item B is bought when item A is bought.
- To assess the reliability of a rule, we use confidence, defined as:
Confidence(A ⇒ B)=Support(A and B) / Support(A)
Example:
Support({leggings, sports bras}) = 0.25
Support({leggings}) = 0.4
Then the confidence of the rule {leggings} → {sports bras} is:Confidence = 0.25 / 0.4 = 0.625
This means that 62.5% of the time, when a customer buys leggings, they also buy sports bras.
04. Thresholds:
- To filter out trivial or weak rules, we set minimum thresholds for both support and confidence.
A rule {A} → {B} becomes actionable only if:
The support of
{A, B}exceeds the minimum support threshold.The confidence of the rule exceeds the minimum confidence threshold.
- Example: Suppose we have Total transactions: 20 while Transactions with leggings: 10 and Transactions with leggings & sports bras: 7. So,
- Support (leggings & sports bras) = 7 / 20 = 0.35
- Confidence (leggings → sports bras) = 7 / 10 = 0.7
- If we set threshold, Minimum Support = 0.3 & Minimum Confidence = 0.6
- As our support & confidence value exceeds threshold, rules is accepted as:
If a customer buys leggings, they’re likely to also buy sports bras.
These thresholds are defined based on business needs, data size, and desired precision.
05. Lift
- How much more likely B is bought when A is bought compared to random chance.
Lift(A ⇒ B)=Confidence(A ⇒ B) / Support(B)
If Lift > 1: Positive correlation
If Lift = 1: No correlation
If Lift < 1: Negative correlation
Association Rule Mining Approach
1. Brute-Force Approach
How It Works:
Generates all possible item combinations (itemsets)
Calculates support and confidence for every rule
Keeps rules that pass minimum thresholds
Example:
If you sell {leggings, sports bras, hoodies},It will test every combination:
{leggings, sports bras} → hoodie
{leggings} → {sports bras, hoodie}
…
Pros:
Simple to understand
Guarantees completeness
Cons:
Computationally expensive
Exponential growth: For N items → 2^N itemsets
Not scalable for large datasets
Real-World Use:
- Not practical for real datasets unless N is very small.
2. Two-Step Approach
How It Works:
- Step 01: Frequent Itemset Generation
Generate all itemsets whose support exceeds the support threshold
Step 02: Rule Generation
From those itemsets, generate rules like
{leggings, sports bra} → {hoodie}.Keep only those rules that meet a minimum confidence threshold.
Algorithms That Use This Approach
1. Apriori Algorithm
- How it works:
- Start with One Item at a Time
- Look at all single items (like “leggings”, “sports bra”, etc.).
- Keep only those that appear frequently enough (based on a minimum support threshold).
- Combine Items to Make Larger Sets
- Now, combine frequent 1-itemsets to make 2-itemsets, like:
{leggings, sports bra}
- Now, combine frequent 1-itemsets to make 2-itemsets, like:
- Start with One Item at a Time
- Check which of these appear often enough in the data.
- Repeat the Process
- Keep increasing the number of items in a set (3-itemsets, 4-itemsets…).
- Only keep the ones that meet the support threshold.
- Stop when you can’t find any more frequent itemsets.
- Prune Unwanted Sets
- If a larger itemset includes any smaller infrequent subset, skip it.
- Example: If
{leggings}is not frequent, don’t bother with{leggings, hoodie}.
- Generate Rules
- From the frequent itemsets, create rules like:
{leggings, sports bra} → hoodie - For each rule, calculate confidence (how often the rule is true).
- From the frequent itemsets, create rules like:
- Keep the Strong Rules
- Only keep rules that meet your confidence threshold.
- These are your final association rules.
- Example Rule: From frequent itemset
{leggings, sports bras}, generate: {leggings} → {sports bras}
{sports bras} → {leggings}
- Pros:
- Simple to understand
- Uses pruning to reduce combinations
- Easy to implement (used in
mlxtendPython lib)
- Cons:
- Very slow on large datasets
- Generates many candidate itemsets
- Best for:
- Small to medium datasets
- Learning and teaching concepts
2. FP-Growth(Frequent Pattern Growth) Algorithm
- How it works:
- Builds a compact tree structure (FP-tree) to store frequent patterns.
- Avoids candidate generation altogether.
- Mines frequent patterns directly from the tree
- Example Rule:If
{leggings, trainers}are frequent, FP-tree structure helps find: {leggings} → {trainers} without scanning all combinations.
- Pros:
- Much faster than Apriori
- Uses less memory as no need to generate all candidate itemsets
- Scales well with large datasets
- Cons:
- Slightly harder to implement
- Less intuitive than Apriori
- Best for:
- Large datasets
- Highly practical for large e-commerce or retail datasets.
3. ECLAT(Equivalence Class Clustering) Algorithm (Vertical Mining)
- How it works:
- Uses vertical data format (item → transaction IDs) to find frequent itemsets.
- Finds frequent itemsets via intersection of item lists instead of scanning the entire database.
- Example: If
{leggings}appears in T1, T2, T3 and{sports bras}in T2, T3:
{leggings, sports bras}→ intersection: T2, T3 → support = 2
- Pros:
- Fast for dense data
- Less scanning than Apriori
- Cons:
Memory intensive for sparse or large datasets
Complex data transformation required
- Best for:
- Useful in small dense datasets like medical data.
- Less popular in retail.
04. DHP (Direct Hashing and Pruning)
- How It Works:
- Builds on Apriori
- Uses hashing to reduce the number of candidate itemsets
- Prune transactions and candidates during each step
- Pros:
- Speeds up Apriori
- More efficient in early stages
- Cons:
- Gains are limited
- Still not efficient for very large datasets
- Real-World Use:
- Best as an optimization layer for Apriori, not used alone.
Key Optimization Strategies in Association Rule Mining
- When working with large datasets (think thousands of transactions and products), it’s computationally expensive to analyze every possible combination.
- To solve this, data scientists use 3 key principles:
1. Reduce the Number of Candidates (M)
Problem: With d items, the number of possible itemsets is 2^d (excluding empty and full sets).
For 5 items (A, B, C, D, E), this is 2⁵ = 32 itemsets!
Solution: Use pruning strategies like the Apriori principle:
If
{A, B}is not frequent, then{A, B, C}cannot be frequent either.This allows us to avoid generating many useless itemsets.
2. Reduce the Number of Transactions (N)
Problem: Scanning every transaction for every candidate itemset is slow.
Solution: Use smart algorithms (like DHP or vertical-based mining) to reduce the number of transactions considered as itemsets grow:
DHP (Direct Hashing and Pruning) eliminates infrequent candidates early.
Vertical data format (used in ECLAT) stores items as sets of transaction IDs, reducing the need to scan the full dataset repeatedly.
3. Reduce the Number of Comparisons (N × M)
Problem: Matching every itemset (M) with every transaction (N) leads to N × M comparisons.
Solution:
- Use efficient data structures (e.g., hash trees, FP-Trees) to store transactions and itemsets.
- This avoids comparing every candidate with every transaction explicitly.
Python Implementation for Apriori Algorithm
# Import Necessary Libraries
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Sample Data
dataset = [
['Denim Jacket', 'White Sneakers'],
['Leggings', 'Sports Bra', 'Yoga Mat'],
['Denim Jacket', 'White Sneakers', 'Cap'],
['Leggings', 'Yoga Mat'],
['Denim Jacket', 'Cap'],
]
# Convert to one-hot encoded DataFrame
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_data = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_data, columns=te.columns_)
# Step 1: Find Frequent Itemsets
frequent_itemsets = apriori(df, min_support=0.4, use_colnames=True)
# Step 2: Generate Rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
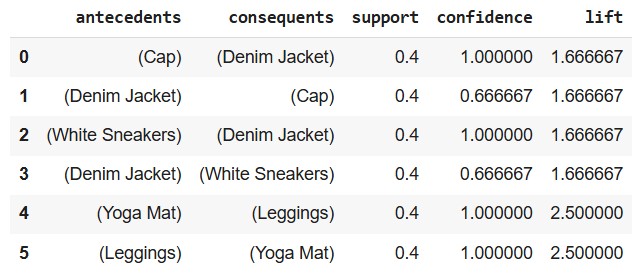
| Column | Meaning |
|---|---|
| antecedents | The “if” part of the rule (the condition) |
| consequents | The “then” part of the rule (the outcome) |
| support | How often both items occur together in all transactions |
| confidence | How often the consequent appears when the antecedent is present |
| lift | How much more likely the consequent is given the antecedent (vs. by chance) |
Insights from the above Table
Row 0
Rule: If Cap, then Denim Jacket
Support: 0.4 → In 40% of transactions, both Cap and Denim Jacket were bought together.
Confidence: 1.0 → Every time Cap was bought, Denim Jacket was also bought.
Lift: 1.67 → Buying a Cap makes the purchase of a Denim Jacket 1.67x more likely than random.
>>> Strong rule with perfect confidence.
Row 1
Rule: If Denim Jacket, then Cap
Support: 0.4 → Same as above, occurs in 40% of transactions.
Confidence: 0.67 → 67% of people who bought a Denim Jacket also bought a Cap.
Lift: 1.67 → Again, this is better than random chance.
>>> Good rule, but not as strong as the reverse.
Row 2
Rule: If White Sneakers, then Denim Jacket
Support: 0.4 → 40% bought both items.
Confidence: 1.0 → Everyone who bought White Sneakers also bought a Denim Jacket.
Lift: 1.67 → Stronger than random chance.
>>> Very strong, could be useful for recommendations.
Row 3
Rule: If Denim Jacket, then White Sneakers
Confidence: 0.67 → Not all Denim Jacket buyers bought White Sneakers.
Still decent, and lift says it’s better than chance.
Row 4
Rule: If Yoga Mat, then Leggings
Support: 0.4 → 40% of people bought both.
Confidence: 1.0 → 100% who bought Yoga Mat also bought Leggings.
Lift: 2.5 → Very strong correlation!
>>> Excellent rule. Yoga Mat buyers are very likely to want Leggings too.
Row 5
Rule: If Leggings, then Yoga Mat
Same numbers but reversed. Also 100% confidence, 2.5 lift.
>>>Suggests that Yoga-related items are tightly linked.
Now we can:
Recommend Denim Jacket when someone adds White Sneakers to cart.
Bundle Cap + Denim Jacket or Leggings + Yoga Mat.
Python Implementation for FP-Growth Algorithm
# Import Necessary Libraries
from mlxtend.preprocessing import TransactionEncoder
import pandas as pd
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.frequent_patterns import association_rules
# Sample
dataset = [
['Denim Jacket', 'White Sneakers'],
['Leggings', 'Sports Bra', 'Yoga Mat'],
['Denim Jacket', 'White Sneakers', 'Cap'],
['Leggings', 'Yoga Mat'],
['Denim Jacket', 'Cap']
]
# Convert dataset to one-hot encoded format
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# Minimum support can be adjusted (e.g., 0.4 = 40%)
frequent_itemsets = fpgrowth(df, min_support=0.4, use_colnames=True)
# Creating Rules
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.6)
rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']]
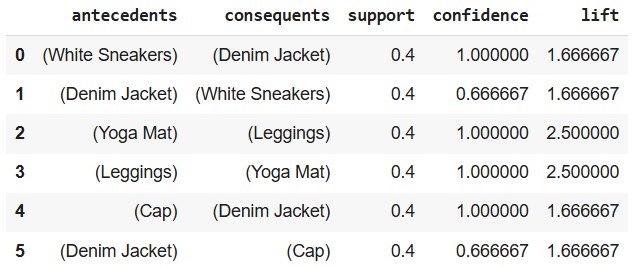
Comparison between Apriori vs FP-Growth
| Feature | Apriori | FP-Growth |
|---|---|---|
| Strategy | Candidate generation | Tree-based (no candidates) |
| Memory usage | High (if many items) | More efficient |
| Speed | Slower | Faster |
| Code Simplicity | Simple | Slightly more complex |
