Bagging:
- Bagging (short for Bootstrap Aggregating) is an ensemble learning technique commonly used to reduce variance, especially in models prone to overfitting on noisy datasets.
- In bagging, multiple models are trained on different random subsets of the training data, where each subset is created through sampling with replacement (i.e., the same data point can appear more than once in a given subset).
- For regression tasks, the final prediction is typically the average (mean) of the outputs from all models.
- For classification tasks, the final prediction is usually determined by majority voting, i.e., the class that receives the most votes from the individual models is chosen as the final output.
How Bagging Works:
Bootstrapping:
- Bagging uses a bootstrapping sampling technique to create diverse training subsets.
- This resampling method generates different subsets of the original training dataset by selecting data points randomly and with replacement.
- This means that each time a data point is selected, it can be chosen multiple times, and some data points may not be selected at all.
- As a result, a single data point may appear multiple times in a given sample, while others may be absent.
Parallel Training:
- Each bootstrapped dataset is used to train a separate base learner.
- Since these models are trained independently, the process can be parallelized, which makes bagging both efficient and scalable, especially with modern computing resources.
A base learner (also called a weak learner) is a simple model used as the building block in an ensemble learning method like bagging, boosting, or stacking. In bagging, such as Random Forests, the base learner is usually a decision tree.
Aggregation:
Depending on the task, the predictions from individual models are aggregated to produce a final output that is more accurate and stable.
In regression, the final prediction is the average of all the outputs from the individual base learners.
In classification, the final prediction is determined by majority voting—the class that receives the most votes from the base learners is selected. This is known as hard voting.
Hard voting = selecting the class with the most votes.
Soft voting (used in some ensemble methods like VotingClassifier) = averaging predicted class probabilities and selecting the class with the highest average probability.
Soft voting is not typically used in bagging, since base learners (like decision trees) often don’t produce probabilities by default.
Pros of Bagging:
Easy to implement using libraries like Scikit-learn with built-in support for ensemble models.
Reduces variance, improving model stability and generalization.
Supports parallel training, making it efficient on large datasets.
Cons of Bagging:
Less interpretable, as combining multiple models makes it harder to explain results.
Increased computational cost due to training many models.
Doesn’t reduce bias, so it’s less effective with underfitting models.
Python Implementation for Bagging
# Import Necessary libraries
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.datasets import fashion_mnist
import numpy as np
import matplotlib.pyplot as plt
# Load Fashion MNIST
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# Reshape and scale
X_train = X_train.reshape(-1, 28 * 28).astype(np.float32)
X_test = X_test.reshape(-1, 28 * 28).astype(np.float32)
# Normalize
X_train = X_train / 255.0
X_test = X_test / 255.0
# Define base learner
base_model = DecisionTreeClassifier(max_depth=10)
# Define bagging classifier
bagging_clf = BaggingClassifier(
estimator=base_model,
n_estimators=25,
max_samples=0.8,
bootstrap=True,
n_jobs=-1,
random_state=42
)
# Train model
bagging_clf.fit(X_train, y_train)
# Predict and evaluate
y_pred = bagging_clf.predict(X_test)
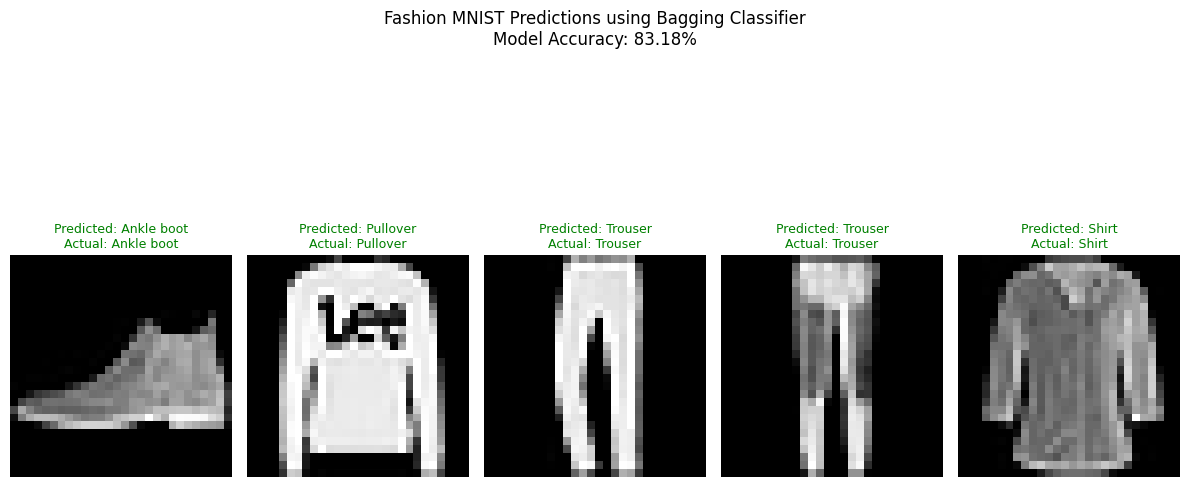
Bagging_Accuracy = accuracy_score(y_test, y_pred)
# Visualize predictions
fashion_labels = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Reshape back to 28x28 for visualization
X_test_images = X_test.reshape(-1, 28, 28)
plt.figure(figsize=(12, 6))
for i in range(5):
plt.subplot(1, 5, i+1)
plt.imshow(X_test_images[i], cmap='gray')
plt.title(f"Predicted: {fashion_labels[y_pred[i]]}\nActual: {fashion_labels[y_test[i]]}",
color='green' if y_pred[i] == y_test[i] else 'red',
fontsize=9)
plt.axis('off')
plt.suptitle(f"Fashion MNIST Predictions using Bagging Classifier\nModel Accuracy: {Bagging_Accuracy:.2%}", y=1.05)
plt.tight_layout()
plt.show()